Generative AI in the Enterprise: the Best Argument Yet For Data Lifecycle Management
If you were one of those companies that kinda ignored data lifecycle management, well, AI is going to make you regret that.


I was talking to someone recently and they mentioned that they had been asked about using "public" AI models at work. They remembered that their Acceptable Use Policy (2026) had provisions in it about that, so they asked their corporate AI system to pull that information up. The AI system pulled up the 2013 AUP.
As individuals we all have different approaches to data retention. Some of us don't keep a scrap of paper, email, or anything else longer than we have to. One of my relatives goes through their text messages weekly and deletes anything older than a few days. Others hoard everything - digital or on paper - for as long as they possibly can. I bet we all know somebody who still has copies of their tax returns dating back to the Reagan administration.
But for whatever reason companies seem to be especially adept hoarders of data. Hey, storage is cheap, am I right? (sorry, I know you just read that in the voice I intended you to read it in, and I'm both ashamed and proud) And that's always been a problem, because it leads to data breaches having an even larger impact than they need to be - like T-Mobile losing the data of people that haven't had an account with them for years as an example. And that's just one extremely easy to recall example, they are in no way alone.
However that clearly hasn't been the compelling reason for companies to change their ways. I'm hoping that the emergence of AI helps change that.
AI's Temporal Anomaly

All the screwiest science fiction plot lines seem to involve a "temporal anomaly." Whether it's Data's head being buried below San Francisco in the 1910's, or Philip J Fry becoming his own grandfather at Roswell, or John Chrichton searching for Katrazi, time travel is always just plain weird, never mind what that one guy did with a DeLorean. AI seems to have it's own temporal anomaly - which is to say that it just doesn't seem to have a good grasp of time.
There are countless examples of GenAI's inability to understand the linearity of time, including that it can tell you that several US presidents have all graduated the University of Wisconsin Madison, even though many of them seem to have graduated long after their deaths.
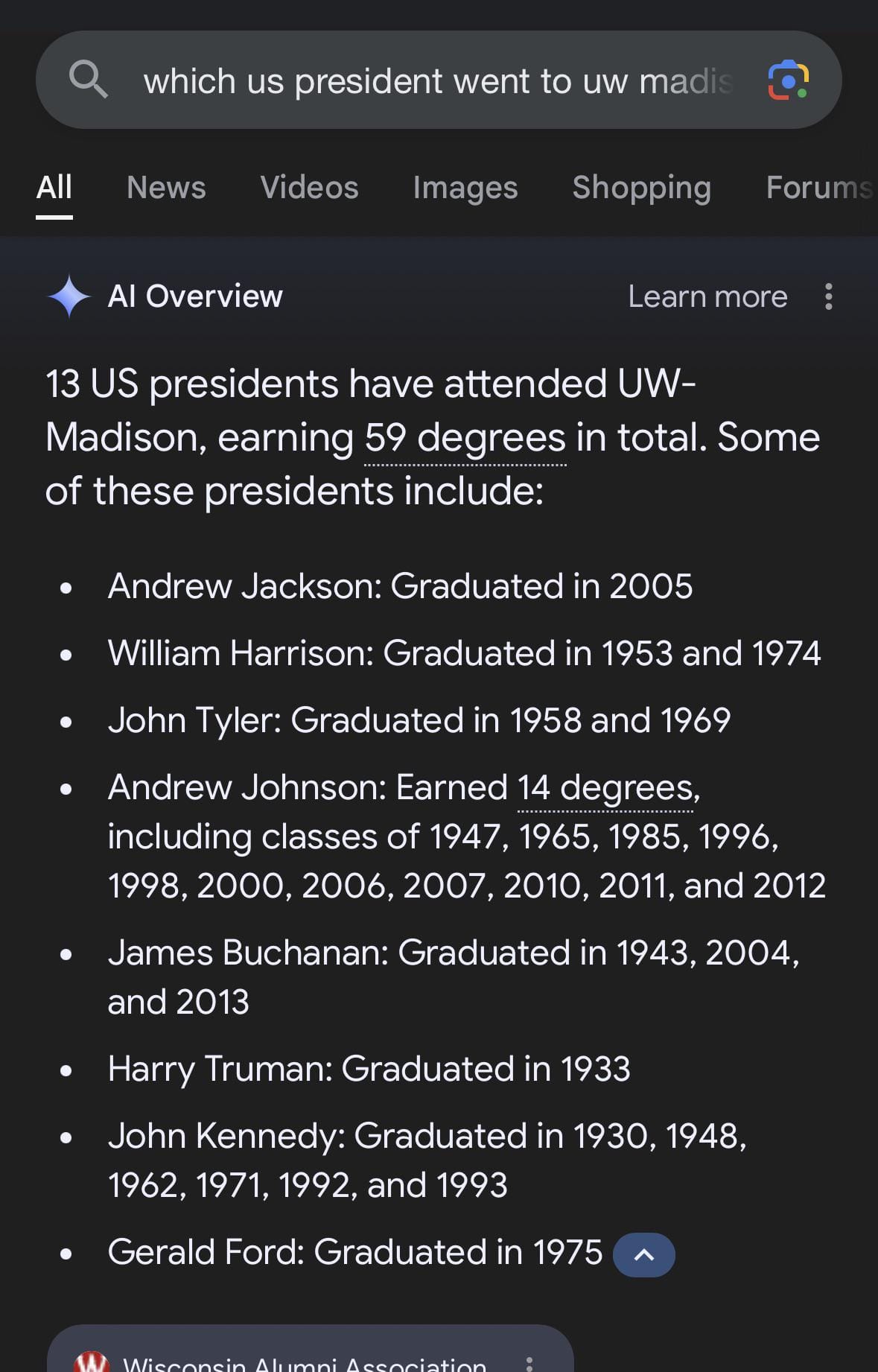
But to get back to the example at the start of this post, you would hope that AI could grasp the concept that the current AUP is different than the one from thirteen years prior. It just seems that current GenAI models don't really recognize that things change over time.
But let's be fair, that can be difficult for any of us. As a practical example, allow me to explain how sales presentations get continuously abused and rebuilt by earnest salespeople and sales engineers.
I might be searching for the latest version of a sales preso and I find three copies on a file share with different dates: one from two months ago, one from last month, and one from this week. They have identical file names, and no version numbers associated with them, so I'm stuck with looking at "last edited" dates. So I look deeper:
- The file from 2 months ago talks about something we have released as "coming soon." So that one is clearly not correct.
- The file from 1 month ago looks ok, and has the updated slide about that new feature.
- The file from this week has some prospect's logo all over it and the old slides about the coming soon feature.
So sure, this can be difficult to do without spending a lot of time and energy if you don't have your ducks in a row already.
Data Lifecycle Management
So that all brings me to this: we do a horrible job at data lifecycle management within companies and corporations. But if I'm going to make such a sweeping statement I should probably be kind enough to define Data Lifecycle Management, shouldn't I? Let's use this definition:
Data Lifecycle Management is the management of data from the time it is created or ingested through to the scheduled retirement and destruction of that data. Included in this lifecycle are the sub-categories of data classification and acceptable data usage.
Yes, before you drop your device and run away screaming, I do believe all of those things are part of data lifecycle management. And I concede that few organizations pay much more than lip service to it, with the exception of heavily regulated data, like HIPAA, PCI, and other specific data types. Let's just dive in a bit further.
Data Creation, Retirement, and Destruction

Lots of data is only truly useful for a relatively short period of time for most purposes. For my general purposes I only need to know the current temperature when I'm heading outside so I can plan out what I'm wearing. However, scientists need to keep track of current temperatures for decades if not centuries in order to identify trends and changes in the climate. That doesn't mean that I, specifically, need to keep that data on their behalf.
Sometimes data must be kept for regulatory or compliance reasons, such as most companies are prompted to keep security logs for a one year period. People and companies are told to keep tax returns for several years, which may differ depending on your locale and filing status.
But after a period of time the data usually becomes a liability. At best it costs money to store the data somewhere, at worst it becomes data that could be compromised via a breach leading to an incident for the organization. This is why companies should develop a retirement and destruction plan for all data.
When I talk about retirement I mean effectively the same as archiving the data - moving it from active use and possible modification to a "read only" state for historical purposes, as there is often a need to be able to refer to older data for trend analysis and other purposes.
Data destruction is exactly what it sounds like: the deletion and destruction of data after whatever time it becomes a liability instead of an asset. This should generally be expressed in a timeframe as opposed to on a case-by-case basis to ensure that data is not accidentally destroyed too soon, nor held for too long.
Referring back to our 2013 Acceptable Use Policy, I'd argue that such a document could probably have been retired in 2015 and destroyed in 2020 under a well defined Data Lifecycle Management Program.
Data Classification
This one is the one every organization at least pays lip service to, generally with three categories:
- Public Data - data that can be shared freely with anyone
- Non-Public Data - stuff we share only with trusted organizations, usually after an NDA has been agreed to
- Private Data - stuff that even most of the people in the organization don't get to see
That's nice and all, but what are the rules that govern this data? When is it deemed retired or destroyed? When does the clock start ticking?
Acceptable Data Use
A further dimension of a good Data Lifecycle Management program is going beyond "who can see this data" and adding "what we allow to be done with the data" to the program. For example, GDPR generally states that if you collect my date of birth to validate I'm old enough to interact with your services you can't use it to send me a "happy birthday" message every year unless you've explicitly told me you're going to do that. But beyond personal information there's plenty of other data that we should be careful about how we allow it to be used even by those who have access to it. That includes how they're allowed to modify it - something we often overlook.
GenAI Crashes the Party
So now we've got this GenAI solution inside our organization, and it has access to all the data. (What classifications are we allowing it to have access to?) We've never done a good job of retiring or deleting old data - except the security logs, those roll over every 365 days because storage isn't that cheap - and we just let the AI loose like a fox in the hen-house, what could possibly go wrong? I'm going to suggest three main things:
- The AI may have access to all the different classifications of data, but how have we set it to be sure the users only have access to the data they should have access to? After all, the public data is still different from the non-public and the private data, so how are we making sure that Bill in shipping and receiving doesn't have access via the AI to the private payroll data?
- The AI doesn't know that the AUP from 13 years ago has been superseded up to 13 times. For it, all the AUP's are just inputs to an overall AUP concept, and the output you get from asking about the AUP is going to be a crapshoot at best. Now let's pretend you're trying to build an earnings report, or prep for an M&A exercise - are you comfortable with the idea that the AI may be calling up old, out of date, data?
- What's your risk acceptance for when a 3rd party compromises your GenAI system and starts sucking all your sensitive content out the front door? How will you really know what was taken if it's all taken from the AI and not from the actual original files and data sources? (Hopefully the AI has read-only access to all this data too right?)
Each of those feels like a recipe for disaster to me, and I think of the three you can appreciate how at least one of them applies to your organization. A strong data lifecycle management program can help mitigate these concerns.
Good News: This Isn't a Cybersecurity Problem To Solve
If you thought it was I'm glad to share with you that you're mistaken. Of course cybersecurity is part of the solution, but such an overarching data governance program must be owned and managed by the business. If cybersecurity tries to own this the program simply won't function - the business will disagree with the restrictions that are being "arbitrarily" placed around data by a "cost center." However, gathering your allies in legal, governance, and corporate risk will help you begin to develop a program that the business can adopt, own, and embrace.
Keep in mind that on the whole we haven't done a good job of this before adding AI into the mix, and this will seem like it could be a delay to AI adoption. Be sure to focus on how this will enable better AI adoption, better AI results, and further keep Bill in shipping and receiving from posting everybody's salaries on Discord.